Summary
RaptorCast is a specialized multicast message delivery protocol used in MonadBFT to send block proposals from leaders to validators. Block proposals are converted into erasure-coded chunks using the Raptor code in RFC 5053. Each chunk is sent to all validators through a two-level broadcast tree, where the first level is a single non-leader node. Each non-leader node is responsible for serving as the first-level node for a different set of chunks; the proportion of chunk assignments is equal to the validator’s stake weight. RaptorCast thus utilizes the full upload bandwidth of the entire network to propagate block proposals to all validators, while preserving Byzantine fault tolerance.Introduction
The technical description of RaptorCast below relates to block propagation amongst validator nodes participating in consensus. In particular, block propagation to full nodes is handled differently.
- Sending messages directly from the leader to each validator. This is the simplest approach, but it would impose very high upload bandwidth requirements for a leader because block proposals are large - for example, 10,000 transactions at 200 bytes per transaction is 2MB.
- Sending messages from the leader to a few peers, who each re-broadcast to a few peers. This approach would reduce the upload bandwidth requirements for the leader, but it would increase maximum latency to all of the nodes, and it risks message loss if some of the peers are Byzantine and fail to forward the message.
Design requirements
-
Reliable message delivery to all participating consensus nodes is guaranteed if a
2/3supermajority of the stake weight is non-faulty (honest and online). - Upload bandwidth requirements for a validator are linearly proportional to message size and are independent of the total number of participating validators.1
- The worst-case message propagation time is twice the worst-case one-way latency between any two nodes. In other words, the propagation of a message to all intended recipients happens within the round-trip time (RTT) between the two most distant nodes in the network.
- Messages are transmitted with a configurable amount of redundancy (chosen by the node operator). Increased redundancy mitigates packet loss and reduces message latency (recipient can decode sooner and more quickly).
How RaptorCast works
Erasure coding
Messages are erasure-coded by the message originator. Erasure coding means that the message is encoded into a set of chunks, and the message can be decoded from any sufficiently-large subset of the chunks. The specific code used by RaptorCast is a variant of the Raptor code documented in RFC 5053, with some Monad-specific modifications to- improve the encoding efficiency of small messages
- reduce the computational complexity of message encoding (at the cost of a slight increase in decoding complexity)
Message and chunk distribution model
RaptorCast uses a two-level broadcast tree for each chunk. The message originator is the root of the tree, a single non-originator node lives at level 1, and every other node lives at level 2. Each chunk of the encoded message potentially corresponds to a different broadcast tree, but the current implementation uses the same broadcast tree for contiguous ranges of the encoded message chunk space. The following diagram illustrates this chunk distribution model: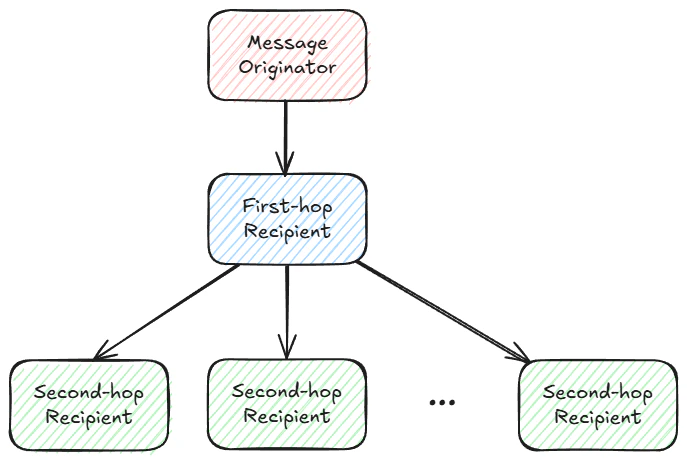
Generic view of the two-hop Raptorcast broadcast tree.
Using a two-level broadcast tree minimizes latency for message delivery. Each level of the tree has worst-case latency of the one-way latency between any two nodes in the network (the network’s “latency diameter”), so the worst case delivery time under RaptorCast is the round-trip-time of the network.Fault tolerance
RaptorCast runs directly over UDP, with a single message chunk per UDP packet.
- 20% network packet loss
- maximum 33% of the network is faulty or malicious
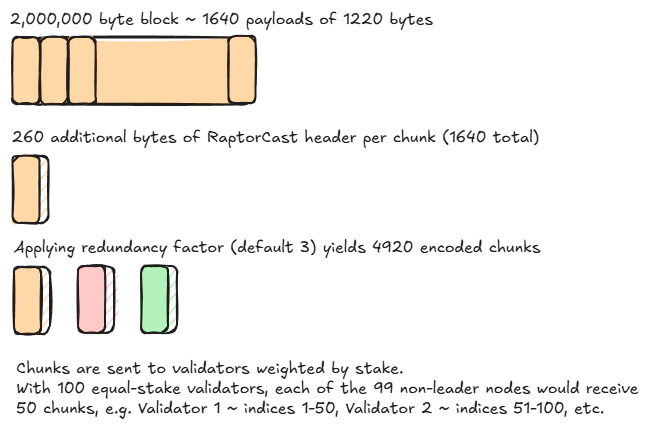
A 2 MB block is split into chunks, expanded and disseminated.
Note that the two-stage distribution model allows participating consensus nodes to receive a copy of a message even if direct network connectivity with the message originator is intermittently or entirely faulty.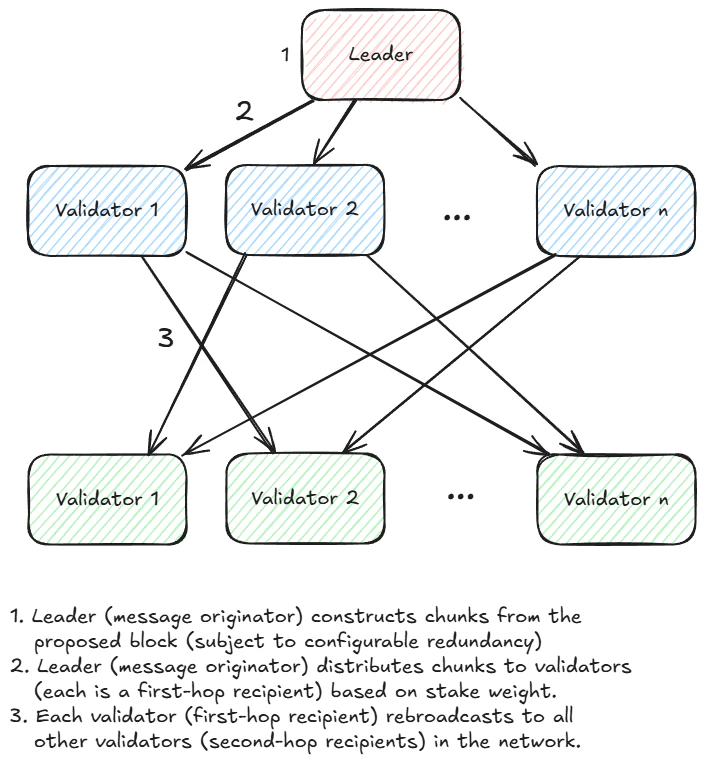
RaptorCast used to send erasure-encoded chunks from a leader to each validator.
The message originator (leader) typically2 distributes generated chunks to the first-hop recipients according to stake weight. For example:- Validator 1 has stake 1
- Validator 2 has stake 2
- Validator 3 has stake 3
- Validator 4 has stake 4
- 2 / (2 + 3 + 4) of generated chunks to validator 2
- 3 / (2 + 3 + 4) of generated chunks to validator 3
- 4 / (2 + 3 + 4) of generated chunks to validator 4
Chunk transport integrity
The originator signs every encoded chunk, so intermediate nodes (level one) in the broadcast tree can verify the integrity of an encoded chunk before forwarding it. Furthermore, the number of source chunksK is encoded in the message. For given K, the recipient currently accepts encoded chunks in the range of 0 to 7 * K - 1. This gives the originator sufficient freedom to specify a high degree of redundancy (up to 7), while also limiting the potential for network spam by a rogue validator.
To amortize the cost of generating and verifying these signatures over many chunks, RaptorCast aggregates contiguous ranges of encoded message chunks in variable-depth Merkle trees, and produces a single signature for every Merkle tree root.
Other uses of RaptorCast
RaptorCast is not only used for broadcasting a block in chunks from the leader.Transaction forwarding
Transaction forwarding, e.g. from a full node to the next three validator hosts, is performed via RaptorCast, benefiting from its properties of speed and robustness. In this context, only one hop is required - the receiver should not rebroadcast.Secondary RaptorCast - full node block propagation
RaptorCast is also used to disseminate block proposals to full nodes. As described in full node configurations, each participating validator creates a secondary RaptorCast network rooted in itself, utilizing full nodes as the recipients. Full nodes are added to a validator’s secondary RaptorCast group if they are prioritized by the validator, or if they are running in public mode and are selected by the selection algorithm.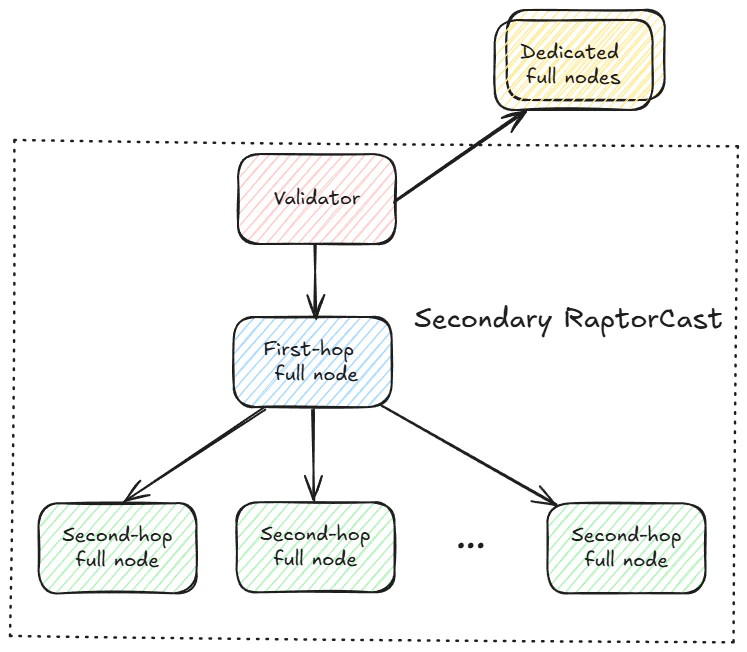
Each validator, after reconstructing the proposal, can disseminate all received (or produced) chunks to full nodes via dedicated relationship or secondary RaptorCast.
Secondary RaptorCast mirrors the primary RaptorCast diagram above. Under secondary RaptorCast, the originator is now any validator, and the group receiving chunks is a collection of public and prioritized full nodes, rather than the stake-weighted validator set. All full nodes in secondary RaptorCast receive an equal number of chunks (no stake-weight applicable). In terms of bandwidth, secondary RaptorCast is much more efficient than dedicated full nodes, because the upload bandwidth requirement for the validator is constant, rather than scaling linearly for the number of dedicated full nodes. Similar to primary RaptorCast, by adding a second hop, the burden of dissemination is borne more evenly by the participants in the group.Footnotes
- This holds when participating validators are (approximately) equally staked. In situations with (very) unevenly distributed stake weights, we need to deviate from the equal-upload property in order to maintain reliable message delivery for every possible scenario where two-thirds of the stake weight corresponds to non-faulty nodes. ↩
- The pure stake-weighted distribution scheme can break down when the number of required chunks is sufficiently small, e.g. 12 chunks distributed to 100 validators. This corner case is actively being addressed. ↩